2024 하계 모각코 회고
회고 처음에 인공지능에 관한 논문을 찾아보며 공부를 하기로 계획 했지만 아직 이 분야에 대한 지식이 많이 부족해 논문을 보며 완전한 이해는 아니더라도 얻어갈 수 있는 것이 있을지, 논문을 어떤 식으로 읽어가야 하는지에 대해 걱정을 많이 했다. 물론 처음에는 막막했지만 계속해서 ...
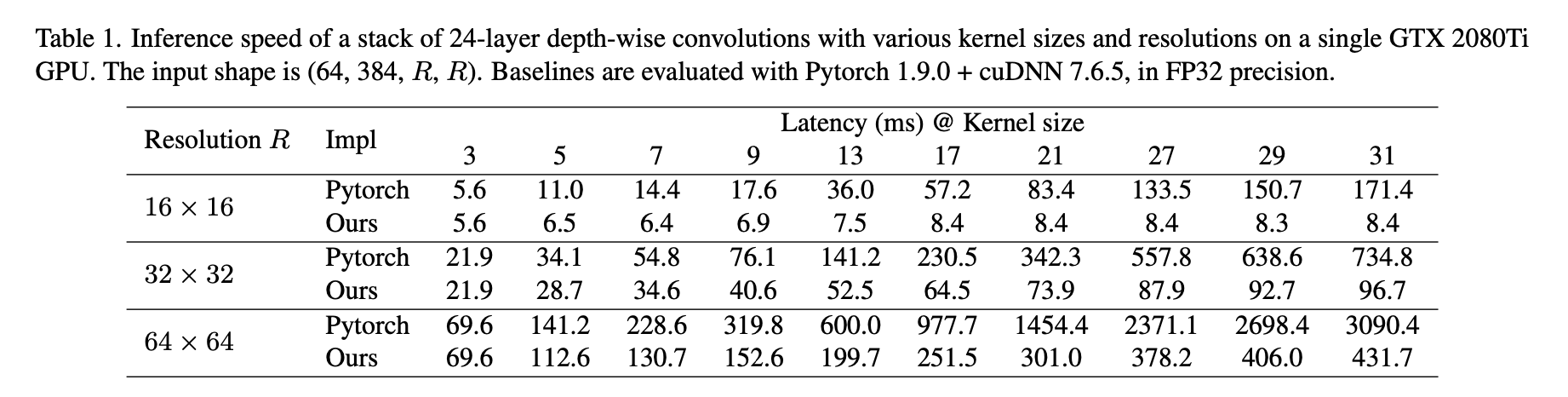
Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs
: Vit 에서 영감을 받아 큰 커널을 사용하는 CNN 구조를 제안하게 됨 -> 이 방법은 작은 커널을 여러개 사용하는 대신 몇 개의 큰 커널을 사용하는 것이 더 효율적임을 보여줌
: 기존의 Regional dropout은 informative한 픽셀의 정보를 까맣게 처리하거나 무작위 노이즈로 처리함 -> 이로인해 정보손실 + 비효율성을 초래해 바람직하지 않다고 받아들여짐 -> CutMix 라는 증강 기법을 제안
: 한 이미지의 패치를 잘라내어 훈련 이미지에 붙이고 라벨도 똑같이 섞어줌 -> 입력 데이터의 일부를 무작위로 제거하는 Regional dropout과 유사한 정규화 효과를 제공해 과적합을 방지


회고 처음에 인공지능에 관한 논문을 찾아보며 공부를 하기로 계획 했지만 아직 이 분야에 대한 지식이 많이 부족해 논문을 보며 완전한 이해는 아니더라도 얻어갈 수 있는 것이 있을지, 논문을 어떤 식으로 읽어가야 하는지에 대해 걱정을 많이 했다. 물론 처음에는 막막했지만 계속해서 ...
논문 리뷰
논문 리뷰
논문 리뷰
논문 리뷰
논문 리뷰
논문 리뷰
계획 Challenge1) SAR segmentation (7.18 발표)